Previous posts in this series:
Silent Duels and an Old Paper of Restrepo Silent Duels—Parsing the Construction
Last time we waded into Restrepo’s silent duel paper. You can see the original and my re-typeset version on Github along with all of the code in this series. We digested Section 2 and a bit further, plotting some simplified examples of the symmetric version of the game.
I admit, this paper is not an easy read. Sections 3-6 present the central definitions, lemmas, and proofs. They’re a slog of dense notation with no guiding intuition. The symbols don’t even get catchy names or “think of this as” explanations! I think this disparity in communication has something to do with the period in which the paper was written, and something to do with the infancy of computing at the time. The paper was published in 1957, which marked the year IBM switched from vacuum tubes to transistors, long before Moore’s Law was even a twinkle in Gordon Moore’s eye. We can’t blame Restrepo for not appealing to our modern sensibilities.
I spent an embarrassing amount of time struggling through Sections 3-6 when I still didn’t really understand the form of the optimal strategy. It’s not until the very end of the paper (Section 8, the proof of Theorem 1) that we get a construction. See the last post for a detailed description of the data that constitutes the optimal strategy. In brief, it’s a partition of $ [0,1]$ into subintervals $ [a_i, a_{i+1}]$ with a probability distribution $ F_i$ on each interval, and the time you take your $ i$-th action is chosen randomly according to $ F_i$. Optionally, the last distribution can include a point-mass at time $ t=1$, i.e., “wait until the last moment for a guaranteed hit.”
Section 8 describes how to choose the $ a_i$’s and $ b_j$’s, with the distributions $ F_i$ and $ G_j$ built according to the formulas built up in the previous sections.
Since our goal is still to understand how to construct the solution—even if why it works is still a mystery—we’ll write a program that implements this algorithm in two posts. First, we’ll work with a simplified symmetric game, where the answer is provided for us as a test case. In a followup post, we’ll rework the code to construct the generic solution, and pick nits about code quality, and the finer points of the algorithm Restrepo leaves out.
Ultimately, if what the program outputs matches up with Restrepo’s examples (in lieu of understanding enough of the paper to construct our own), we will declare victory—we’ll have successfully sanity-checked Restrepo’s construction. Then we can move on to studying why this solution works and what caveats hide beneath the math.
Follow the Formulas
The input to the game is a choice of $ n$ actions for player 1, $ m$ actions for player 2, and probability distributions $ P, Q$ for the two player’s success probabilities (respectively). Here’s the algorithm as stated by Restrepo, with the referenced equations following. If you’re following along with my “work through the paper organically” shtick, I recommend you try parsing the text below before reading on. Recall $ \alpha$ is the “wait until the end” probability for player 1’s last action, and $ \beta$ is the analogous probability for player 2.

Restrepo’s description of the algorithm for computing the optimal strategy.
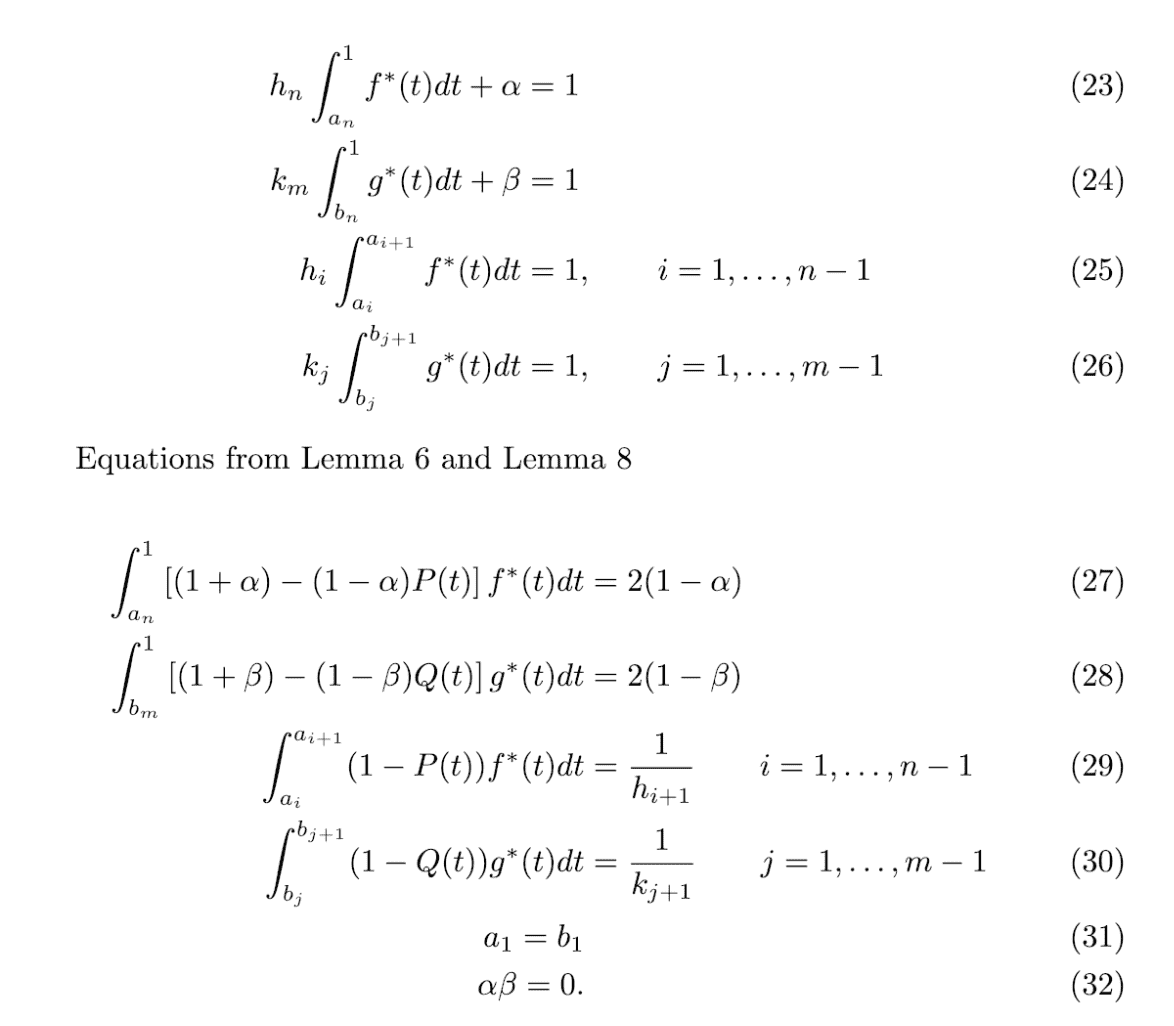
The equations referenced above
Let’s sort through this mess.
First, the broad picture. The whole construction depends on $ \alpha, \beta$, these point masses for the players’ final actions. However, there’s this condition that $ \alpha \beta = 0$, i.e., at most one can be nonzero. This makes some vaguely intuitive sense: a player with more actions will have extra “to spare,” and so it may make sense for them to wait until the very end to get a guaranteed hit. But only one player can have such an advantage over the other, so only one of the two parameters may be nonzero. That’s my informal justification for $ \alpha \beta = 0$.
If we don’t know $ \alpha, \beta$ at the beginning, Restrepo’s construction (the choice of $ a_i$’s and $ b_j$’s) is a deterministic function of $ \alpha, \beta$, and the other fixed inputs.
$$\displaystyle (\alpha, \beta) \mapsto (a_1, \dots, a_n, b_1, \dots, b_m)$$The construction asserts that the optimal solution has $ a_1 = b_1$ and we need to find an input $ (\alpha, \beta) \in [0,1) \times [0,1)$ such that $ \alpha \beta = 0$ and they produce $ a_1 = b_1 = 1$ as output. We’re doing a search for the “right” output parameters, and using knowledge about the chained relationship of equations to look at the output, and use it to tweak the input to get the output closer to what we want. It’s not gradient descent, but it could probably be rephrased that way.
In particular, consider the case when we get $ b_1 < a_1$, and the other should be clear. Suppose that starting from $ \alpha = 0, \beta = 0$ we construct all our $ a_i$’s and $ b_j$’s and get $ b_1 < a_1$. Then we can try again with $ \alpha = 0, \beta = 1$, but since $ \beta = 1$ is illegal we’ll use $ \beta = 1 – \varepsilon$ for as small a $ \varepsilon$ as we need (to make the next sentence true). Restrepo claims that picking something close enough to 1 will reverse the output, i.e. will make $ a_1 < b_1$. He then finishes with (my paraphrase), “obviously $ a_1, b_1$ are continuous in terms of $ \beta$, so a solution exists with $ a_1 = b_1$ for some choice of $ \beta \neq 0$; that’s the optimal solution.” Restrepo is relying on the intermediate value theorem from calculus, but to find that value the simplest option is binary search. We have the upper and lower bounds, $ \beta = 0$ and $ \beta = 1 – \varepsilon$, and we know when we found our target: when the output has $ a_1 = b_1$.
This binary search will come back in full swing in the next post, since we already know that the symmetric silent duel starts with $ a_1 = b_1$. No search for $ \alpha, \beta$ is needed, and we can fix them both to zero for now—or rather, assume the right values are known.
What remains is to determine how to compute the $ a_i$’s and $ b_j$’s from a starting $ \alpha, \beta$. We’ll go through the algorithm step by step using the symmetric game where $ P=Q$ (same action success probability) and $ n=m$ (same action count) to ground our study. A followup post will revisit these formulas in full generality.
The symmetric game
The basic idea of the construction is that we start from a computation of the last action parameters $ a_n, b_m$, and use those inductively to compute the parameters of earlier actions via a few integrals and substitutions. In other words, the construction is a recursion, and the interval in which the players take their last action $ [a_n, 1), [b_m, 1)$ is the base case. As I started writing the programs below, I wanted to give a name to these $ a_i, b_j$ values. Restrepo seems to refer to them as “parameters” in the paper. I call them transition times, since the mark the instants at which a player “transitions” from one action interval $ [a_2, a_3]$ to the next $ [a_3, a_4]$.
For a simple probability function $ P$, the end of the algorithm results in equations similar to: choose $ a_t$ such that $ P(a_{n-t}) = 1/(2t + 3)$.
Recall, Player 1 has a special function used in each step to construct their optimal strategy, called $ f^*$ by Restrepo. It’s defined for non-symmetric game as follows, where recall $ Q$ is the opponent’s action probability:
$$\displaystyle f^*(t) = \prod_{b_j > t} (1-Q(b_j))\frac{Q'(t)}{Q^2(t)P(t)}$$[Note the $ Q^2(t)$ is a product $ Q(t)Q(t)$; not an iterated function application.]
Here the $ b_j > t$ asks us to look at all the transition times computed in previous recursive steps, and compute the product of an action failure at those instants. This is the product $ \prod (1-Q(b_j))$. This is multiplied by a mysterious fraction involving $ P, Q$, which in the symmetric $ P=Q$ case reduces to $ P'(t) / P^3(t)$. In Python code, computing $ f^*$ is given below—called simply “f_star” because I don’t yet understand how to interpret it in a meaningful way. I chose to use SymPy to compute symbolic integrals, derivatives, and solve equations, so in the function below, prob_fun and prob_fun_var are SymPy expressions and lambdas.
from sympy import diff
def f_star(prob_fun, prob_fun_var, larger_transition_times):
'''Compute f* as in Restrepo '57.
In this implementation, we're working in the simplified example
where P = Q (both players probabilities of success are the same).
'''
x = prob_fun_var
P = prob_fun
product = 1
for a in larger_transition_times:
product *= (1 - P(a))
return product * diff(P(x), x) / P(x)**3
In this symmetric instance of the problem we already know that $ \alpha = \beta = 0$ is the optimal solution (Restrepo states that in section 2), so we can fix $ \alpha=0$, and compute $ a_n$, which we do next.
In the paper, Restrepo says “compute without parameters in the definition of $ f^*$” and this I take to mean, because there are no larger action instants, the product $ \prod_{b_j > t}1-P(b_j)$ is empty, i.e., we pass an empty list of larger_transition_times. Restrepo does violate this by occasionally referring to $ a_{n+1} = 1$ and $ b_{m+1} = 1$, but if we included either of these $ P(a_{n+1}) = P(1) = 0$, and this would make the definition of $ f^*$ zero, which would produce a non-distribution, so that can’t be right. This is one of those cases where, when reading a math paper, you have to infer the interpretation that is most sensible, and give the author the benefit of the doubt.
Following the rest of the equations is trivial, except in that we are solving for $ a_n$ which is a limit of integration. Since SciPy works symbolically, however, we can simply tell it to integrate without telling it $ a_n$, and ask it to solve for $ a_n$.
from sympy import Integral
from sympy import Symbol
from sympy.solvers import solve
from sympy.functions.elementary.miscellaneous import Max
def compute_a_n(prob_fun, alpha=0):
P = prob_fun
t = Symbol('t0', positive=True)
a_n = Symbol('a_n', positive=True)
a_n_integral = Integral(
((1 + alpha) - (1 - alpha) * P(t)) * f_star(P, t, []), (t, a_n, 1))
a_n_integrated = a_n_integral.doit() # yes now "do it"
P_a_n_solutions = solve(a_n_integrated - 2 * (1 - alpha), P(a_n))
P_a_n = Max(*P_a_n_solutions)
print("P(a_n) = %s" % P_a_n)
a_n_solutions = solve(P(a_n) - P_a_n, a_n)
a_n_solutions_in_range = [soln for soln in a_n_solutions if 0 < soln <= 1]
assert len(a_n_solutions_in_range) == 1
a_n = a_n_solutions_in_range[0]
print("a_n = %s" % a_n)
h_n_integral = Integral(f_star(P, t, []), (t, a_n, 1))
h_n_integrated = h_n_integral.doit()
h_n = (1 - alpha) / h_n_integrated
print("h_n = %s" % h_n)
return (a_n, h_n)
There are three phases here. First, we integrate and solve for $ a_n$ (blindly according to equation 27 in the paper). If you work out this integral by hand (expanding $ f^*$), you’ll notice it looks like $ P'(t)/P^2(t)$, which suggests a natural substitution, $ u=P(t)$. After computing the integral (entering phase 2), we can maintain that substitution to first solve for $ P(a_n)$, say the output of that is some known number $ Z$ which in the code we call P_a_n, and then solve $ P(a_n) = z$ for $ a_n$. Since that last equation can have multiple solutions, we pick the one between 0 and 1. Since $ P(t)$ must be increasing in $ [0,1]$, that guarantees uniqueness.
Note, we didn’t need to maintain the substitution in the integral, and perform a second solve. We could just tell sympy to solve directly for $ a_n$, and it would solve $ P(a_n) = x$ in addition to computing the integral. But as I was writing, it was helpful for me to check my work in terms of the substitution. In the next post we’ll clean that code up a bit.
Finally, in the third phase we compute the $ h_n$, which is a normalizing factor that ultimately ensures the probability distribution for the action in this interval has total probability mass 1.
The steps to compute the iterated lower action parameters ($ a_i$ for $ 1 \leq i < n$) are similar, but the formulas are slightly different:
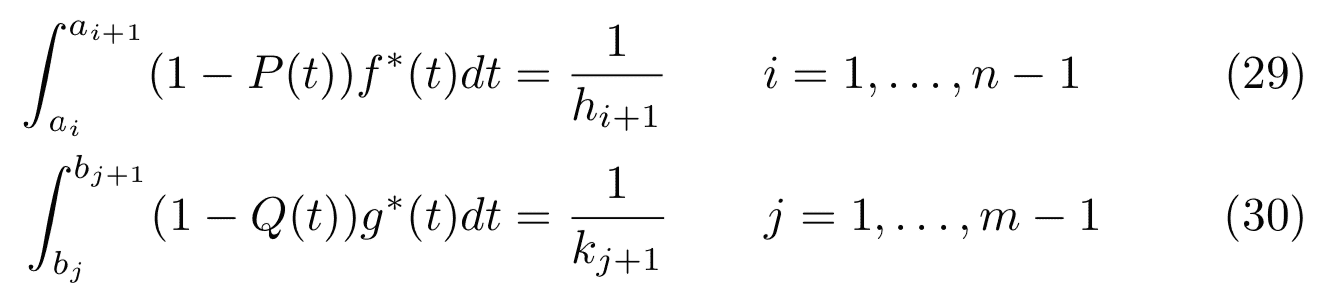
Note that the last action instant $ a_{i+1}$ and its normalizing constant $ h_{i+1}$ show up in the equation to compute $ a_i$. In code, this is largely the same as the compute_a_n function, but in a loop. Along the way, we print some helpful diagnostics for demonstration purposes. These should end up as unit tests, but as I write the code for the first time I prefer to debug this way. I’m not even sure if I understand the construction well enough to do the math myself and write down unit tests that make sense; the first time I tried I misread the definition of $ f^*$ and I filled pages with confounding and confusing integrals!
from collections import deque
def compute_as_and_bs(prob_fun, n, alpha=0):
'''Compute the a's and b's for the symmetric silent duel.'''
P = prob_fun
t = Symbol('t0', positive=True)
a_n, h_n = compute_a_n(prob_fun, alpha=alpha)
normalizing_constants = deque([h_n])
transitions = deque([a_n])
f_star_products = deque([1, 1 - P(a_n)])
for step in range(n):
# prepending new a's and h's to the front of the list
last_a = transitions[0]
last_h = normalizing_constants[0]
next_a = Symbol('a', positive=True)
next_a_integral = Integral(
(1 - P(t)) * f_star(P, t, transitions), (t, next_a, last_a))
next_a_integrated = next_a_integral.doit()
# print("%s" % next_a_integrated)
P_next_a_solutions = solve(next_a_integrated - 1 / last_h, P(next_a))
print("P(a_{n-%d}) is one of %s" % (step + 1, P_next_a_solutions))
P_next_a = Max(*P_next_a_solutions)
next_a_solutions = solve(P(next_a) - P_next_a, next_a)
next_a_solutions_in_range = [
soln for soln in next_a_solutions if 0 < soln <= 1]
assert len(next_a_solutions_in_range) == 1
next_a_soln = next_a_solutions_in_range[0]
print("a_{n-%d} = %s" % (step + 1, next_a_soln))
next_h_integral = Integral(
f_star(P, t, transitions), (t, next_a_soln, last_a))
next_h = 1 / next_h_integral.doit()
print("h_{n-%d} = %s" % (step + 1, next_h))
print("dF_{n-%d} coeff = %s" % (step + 1, next_h * f_star_products[-1]))
f_star_products.append(f_star_products[-1] * (1 - P_next_a))
transitions.appendleft(next_a_soln)
normalizing_constants.appendleft(next_h)
return transitions
Finally, we can run it with the simplest possible probability function: $ P(t) = t$
x = Symbol('x')
compute_as_and_bs(Lambda((x,), x), 3)
The output is
P(a_n) = 1/3 a_n = 1/3 h_n = 1/4 P(a_{n-1}) is one of [1/5] a_{n-1} = 1/5 h_{n-1} = 3/16 dF_{n-1} coeff = 1/8 P(a_{n-2}) is one of [1/7] a_{n-2} = 1/7 h_{n-2} = 5/32 dF_{n-2} coeff = 1/12 P(a_{n-3}) is one of [1/9] a_{n-3} = 1/9 h_{n-3} = 35/256 dF_{n-3} coeff = 1/16
This matches up so far with Restrepo’s example, since $ P(a_{n-k}) = a_{n-k} = 1/(2k+3)$ gives $ 1/3, 1/5, 1/7, 1/9, \dots$. Since we have the normalizing constants $ h_i$, we can also verify the probability distribution for each action aligns with Restrepo’s example. The constant in the point mass function is supposed to be $ h_i \prod_{j={i+1}}^n (1-P(a_j))$. This is what I printed out as dF_{n-k}. In Restrepo’s example, this is expected to be $ \frac{1}{4(k+1)}$, which is exactly what’s printed out.
Another example using $ P(t) = t^3$:
P(a_n) = 1/3 a_n = 3**(2/3)/3 h_n = 1/4 P(a_{n-1}) is one of [-1/3, 1/5] a_{n-1} = 5**(2/3)/5 h_{n-1} = 3/16 dF_{n-1} coeff = 1/8 P(a_{n-2}) is one of [-1/5, 1/7] a_{n-2} = 7**(2/3)/7 h_{n-2} = 5/32 dF_{n-2} coeff = 1/12 P(a_{n-3}) is one of [-1/7, 1/9] a_{n-3} = 3**(1/3)/3 h_{n-3} = 35/256 dF_{n-3} coeff = 1/16
One thing to notice here is that the normalizing constants don’t appear to depend on the distribution. Is this a coincidence for this example, or a pattern? I’m not entirely sure.
Next time we’ll rewrite the code from this post so that it can be used to compute the generic (non-symmetric) solution, see what they can tell us, and from there we’ll start diving into the propositions and proofs.
Until next time!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.