In our last primer we looked at a number of interesting examples of metric spaces, that is, spaces in which we can compute distance in a reasonable way. Our goal for this post is to relax this assumption. That is, we want to study the geometric structure of space without the ability to define distance. That is not to say that some notion of distance necessarily exists under the surface somewhere, but rather that we include a whole new class of spaces for which no notion of distance makes sense. Indeed, even when there is a reasonable notion of a metric, we’ll still want to blur the lines as to what kinds of things we consider “the same.”
The reader might wonder how we can say anything about space if we can’t compute distances between things. Indeed, how could it even really be “space” as we know it? The short answer is: the reader shouldn’t think of a topological space as a space in the classical sense. While we will draw pictures and say some very geometric things about topological spaces, the words we use are only inspired by their classical analogues. In fact the general topological space will be a much wilder beast, with properties ranging from absolute complacency to rampant hooliganism. Even so, topological spaces can spring out of every mathematical cranny. They bring at least a loose structure to all sorts of problems, and so studying them is of vast importance.
Just before we continue, we should give a short list of how topological spaces are applied to the real world. In particular, this author is preparing a series of posts dedicated to the topological study of data. That is, we want to study the loose structure of data potentially embedded in a very high-dimensional metric space. But in studying it from a topological perspective, we aim to eliminate the dependence on specific metrics and parameters (which can be awfully constricting, and even impertinent to the overall structure of the data). In addition, topology has been used to study graphics, image analysis and 3D modelling, networks, semantics, protein folding, solving systems of polynomial equations, and loads of topics in physics.
Recalling Metric Spaces, and Open Sets
Now we turn to generalizing metric spaces. The key property which we wish to generalize is that of open sets. For a metric space, and the reader should be thinking of the real line, the Euclidean plane, or three-dimensional Euclidean space, the open sets are easy to find. One can think of them as just “things without a boundary.” On the real line these look like open intervals $ (a, b)$ and unions of open intervals. In the plane, these would be more like open balls with a fixed center. In other words, it would be the interior of a disk.
To characterize this more mathematically, we define an open ball centered at $ x$ with radius $ \varepsilon$ in the real plane to be the set
$$\displaystyle B(x, \varepsilon) = \left \{ y \in \mathbb{R}^2 | d(x,y) < \varepsilon \right \}$$where $ d$ is the usual Euclidean metric on points in the plane. Whenever someone says open ball, the reader should picture the following:

An open ball of radius r, centered at the point x. [Wolfram Mathworld]
Now of course this doesn’t categorize all of the open sets, since we would expect the union of two of these things to also be open. In fact, it is not hard to see that even if we take an infinite (or uncountable!) union of these open balls centered at any points with any radii, we would still get something that “has no boundary.”
In addition, it appears we can also take intersections. That is, the intersection of two open balls should be open. But we have to be a bit more careful here, because we can break our intuition quite easily. In the case of the real line, I can take an intersection of open intervals which is definitely not open. For example, take the set of intervals $ \left \{ (1-1/n, 1+1/n) : n \in \mathbb{N} \right \}$. If we look at the intersection over all of these intervals, it is not hard to see that
$$\displaystyle \bigcap_{n \in \mathbb{N}} (1- 1/n, 1+1/n) = \left \{ 1 \right \}$$Specifically, the number 1 is in the intersection since it is contained in all of the open intervals. But any number $ x > 1$ cannot be in the intersection because for some large enough $ n$ it must be that $ 1 + 1/n < x$ (just solve this equation for $ n$ as a real number, and then take the ceiling). The case is similar case for $ x < 1$, so the intersection can only be the singleton set 1. This is clearly not an open interval.
So we just found that our intuition for open sets breaks down if we allow for infinite intersections, but everything else seems to work out. Furthermore, the definition of an open ball relied on nothing about Euclidean space except that it has a metric. We’re starting to smell a good definition:
Definition: Let $ X$ be a metric space with metric $ d$. An open set in $ X$ is either:
- A union of any collection of open balls $ B(x, \varepsilon)$ where $ x \in X$, or
- A finite intersection of such open balls.
A set is closed if it is the complement of an open set.
In fact, this characterization of open sets is so good that we can redefine a bunch of properties of metric spaces just in terms of open sets. This is important because in a minute we will actually define a topological space by declaring which sets are open. Before we do that, let’s remain in the friendly world of metric spaces to investigate some of those redefinitions.
Neighborhoods, Sequences, and Continuous Functions
There is an essential switch in going from metric spaces to topological spaces that one must take, and it involves the concepts of neighborhoods.
Definition: Let $ x \in X$ be a point in a metric space $ X$. A neighborhood of $ x$ is any open set $ U$ containing $ x$. More specifically, we can distinguish between an open neighborhood and a closed neighborhood, but without qualifiers we will always mean an open neighborhood.
In particular, the concept of a neighborhood will completely replace the idea of a metric. We will say things like, “for any neighborhood…” and “there exists a neighborhood…”, which will translate in the case of metric spaces to, “for any sufficiently close point…” and “there exists a sufficiently close point…” The main point for this discussion, however, is that if open sets were defined in some other way, the definition would still apply.
Perhaps the simplest example of such a definition is that of a sequence converging. Recall the classical definition in terms of metrics:
Definition: Let $ X$ be a metric space with metric $ d$, and let $ a_n$ be a sequence of elements in $ X$. We say $ a_n$ converges to $ a \in X$ if for any $ \varepsilon > 0$, there is some sufficiently large $ N$ so that the distance $ d(a_n, a) < \varepsilon$ whenever $ n > N$.
In other words, after the $ N$-th point in the sequence, the values will always stay within a tiny distance of $ a$, and we can pick that tiny distance (\varepsilon) arbitrarily close to $ a$. So the sequence must converge to $ a$.
This naturally gives rise to a definition in terms of open neighborhoods of $ a$:
Definition: Let $ X, a_n, a$ be as in the previous definition. We say that $ a_n$ converges to $ a$ if for any open neighborhood $ U$ of $ a$, there is some sufficiently large $ N$ so that $ a_n \in U$ for all $ n > N$.
In particular, these two definitions are equivalent. Before we give the proof, the reader should be warned that pictures will make this proof obvious (but not rigorous), so we encourage the reader to follow along with a piece of paper. Open balls are drawn as circles despite the dimension of the space, and open neighborhoods are usually just drawn as “blobs” containing a certain point.
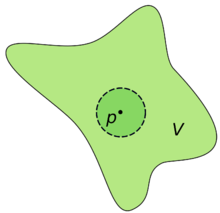
An open neighborhood V of a point p, and an open ball around p contained in V
To see the definitions are equivalent, suppose $ a_n$ converges as in the second definition. Then given an $ \varepsilon$, we can choose a particular choice of open neighborhood to satisfy the constraints of the first definition: just choose the open ball $ B(a, \varepsilon)$. This will translate in terms of the metric precisely to the first definition. Conversely if the first definition holds, all we need to show is that for any open neighborhood $ U$ of any point $ y$, we can always find an open ball $ B(y, \varepsilon)$ contained entirely in $ U$. We can apply this to pick that open ball around $ a$, and use the first definition to show that all of the $ a_n$ will be inside that open ball (and hence inside $ U$) forever onward.
The fact that we can always find such an open ball follows from the triangle inequality. If the open set $ U$ in question is a union of open balls, then the point $ y$ lies within some open ball $ B(x, r)$ where $ x \in U$. The following picture should convince the reader that we can pick a ball around $ y$ contained in $ B(x, r)$

Finding an open ball centered at y inside an open ball centered at x. (source: Wikibooks)
Specifically pick the radius $ \varepsilon$ so that $ d(x,y) + \varepsilon < r$, any point $ z$ inside the ball centered at $ y$ is also in the ball centered at $ x$, and we can see this by simply drawing the triangle connecting these three points, and applying the triangle inequality to show that $ d(x,z) < r$. A similar idea works if $ U$ is a finite intersection of open balls $ B_i$, where we just take the smallest ball around $ y$ of those we get by applying the above picture to each $ B_i$.
The other main definition we want to convert to the language of open sets is that of a continuous function. In particular, when we study metric spaces in pure mathematics, we are interested in the behavior of continuous functions between them (more so, even, than the properties of the spaces themselves). Indeed, when we study calculus in high school and university, this is all we care about: we want to look at minima and maxima of continuous functions, we want to study derivatives (the instantaneous rate of change) of a continuous function, and we want to prove theorems that hold for all continuous functions (such as the mean value theorem).
Identically, in topology, we are interested in the behavior of continuous functions on topological spaces. In fact, we will use special kinds of continuous functions to “declare” two spaces to be identical. We will see by the end of this post how this works, but first we need a definition of a continuous function in terms of open sets. As with neighborhoods, recall the classical definition:
Definition: A function $ f:X \to Y$ of metric spaces with metrics $ d_X, d_Y$ is called continuous if for all $ \varepsilon > 0$ there is a $ \delta > 0$ such that whenever $ d_X(x, y) < \delta$ the distance $ d_Y(f(x), f(y)) < \varepsilon$.
In words, whenever $ x,y$ are close in $ X$, it follows that $ f(x), f(y)$ are close in $ Y$.
Naturally, the corresponding definition in terms of open sets would be something along the lines of “for any open neighborhood $ U$ of $ x$ in $ X$, there is an open neighborhood $ V$ of $ f(x)$ in $ Y$ which contains $ f(U)$.” In fact, this is an equivalent definition (which the reader may verify), but there is a much simpler version that works better.
Definition: A function $ f:X \to Y$ is called continuous if the preimage of an open set under $ f$ is again an open set. That is, whenever $ V \subset Y$ is open, then $ f^{-1}(V)$ is open in $ X$.
The reason this is a better definition will become apparent later (in short: a general topology need not have “good” neighborhoods of a given point $ y$). But at least we can verify these three definitions all coincide for metric spaces. These dry computations are very similar to the one we gave for convergent sequences, so we leave it to those readers with a taste for blood. We will just simply mention that, for example, all polynomial functions are continuous with respect to this definition.
Topological Spaces, a World without Distance
We are now ready to define a general topological space.
Definition: Let $ X$ be any set. A topology on $ X$ is a family of subsets $ T$ of $ X$ for which the following three properties hold:
- The empty set and the subset $ X$ are both in $ T$.
- Any union of sets in $ T$ is again in $ T$.
- Any finite intersection of sets in $ T$ is again in $ T$.
We call the pair $ (X,T)$ a topological space, and we call any set in $ T$ and open set of $ X$.
Definition: A set $ U$ in a topological space $ X$ is closed if its complement is open.
As we have already seen, any metric space $ (X,d)$ is a topological space, where the topology is the set of all open balls centered at all points of $ X$. We say the topology on $ X$ is induced by the metric $ d$. When $ X$ is either $ \mathbb{R}^n$ or $ \mathbb{C}^n$, we call the topology induced by the Euclidean metric the Euclidean topology on $ X$.
But these topological spaces are very well-behaved. We will work extensively with them in our applications, but there are a few classical examples that every student of the subject must know.
If we have any set $ X$, we may define a very silly topology on $ X$ by defining every subset of $ X$ to be open. This family of subsets trivially satisfies the requirements of a topology, and it is called the discrete topology. Perhaps the only interesting question we can ask about this topology is whether it is induced by some metric $ d$ on the underlying space. The avid reader of this blog should be able to answer this question quite easily.
The natural second example after the discrete topology is called the indiscrete topology. Here we simply define the topology as $ T = \left \{ \emptyset, X \right \}$. Again we see that this is a well-defined topology, and it’s duller than a conversation with the empty set.
As a third and slightly less trivial example, we point the reader to our proof gallery, where we define a topology on the integers and use it to prove that there are infinitely many primes.
Note that we can also define a topology on $ X$ by specifying a family of closed sets, as long as any intersection of closed sets is closed, and a finite union of closed sets is closed. This is because of the way unions, intersections, and complements interact. $ (\cup U_i)^{\textup{c}} = \cap U_i^{\textup{c}}$ and vice versa for intersections; proving this is a simple exercise in set theory.
Here is an extended (and vastly more interesting) example. Let $ X = \mathbb{R}^n$, and define a set $ U \subset X$ to be closed if it is the set of common roots of a collection of polynomials in $ n$ variables (which in our example below will be $ x$ and $ y$, but in general are often written $ x_1, \dots, x_n$). The set of roots is also called the zero locus of the collection of polynomials. This topology is called the Zariski topology on $ X$, and it is an extremely important topology in the field of algebraic geometry.
Before we verify that this is indeed a topology on $ X$, let us see a quick example. If $ X = \mathbb{R}^2$, the zero locus of the single polynomial $ y^2 – x^3 – x^2$ is the curve pictured below:
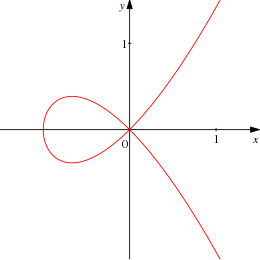
A nodal cubic curve (source Wikipedia).
The red curve is thus a closed set in the Zariski topology, and its complement is an open set. If we add in another polynomial (with a few exceptions) it is not hard to see that their common set of zeroes will either be the empty set or a finite set of points. Indeed, in the Zariski topology every finite set of points is closed. The intrepid reader can try to show that any finite set can be defined using exactly two polynomials (hint: you’ll get a better idea of how to do this in a moment, and without loss of generality, you can ensure one of the two is an interpolating polynomial).
Verifying that the Zariski topology is indeed a topology, it is clear that the empty set and the entire set are closed: the constant polynomial $ 1$ has no roots, and the zero polynomial has all points as its roots. Now, the intersection of any two closed sets is just the union of two collections $ \left \{ f_{\alpha} \right \} \cup \left \{ g_{\beta} \right \}$. By adding more constraints, we only keep the points with are solutions to both the $ f_{\alpha}$ and the $ g_{\beta}$ (despite the union symbol, this truly corresponds to an intersection). Moreover, it is clear that we can take arbitrary unions of families of polynomials and still get a single family of polynomials, which still defines a closed set.
On the other hand, given two closed sets defined by the families of polynomials $ \left \{ f_{\alpha} \right \} , \left \{ g_{\beta} \right \}$, we can achieve their union by looking at the closed set defined by the set of polynomial products $ \left \{ f_{\alpha}g_{\beta} \right \}$ for all possible pairs $ \alpha, \beta$. To show this defines the union, take any point $ x \in \mathbb{R}^n$ which is in the union of the two closed sets. In other words, $ x$ is simultaneously a zero of all $ f_{\alpha}$ or all $ g_{\beta}$. Since every polynomial in this new collection has either an $ f$ factor or a $ g$ factor, it follows that $ x$ is simultaneously a root of all of them. Conversely, let $ x$ is a simultaneous root of all of the $ f_{\alpha}g_{\beta}$. If it weren’t a common zero of all the $ f_{\alpha}$ and it weren’t a common zero of all the $ g_{\beta}$, then there would be some $ \alpha^*$ for which $ x$ is not a root of $ f_{\alpha^*}$ and similarly some $ \beta^*$ for which $ x$ is not a root of $ g_{\beta^*}$. But then $ x$ could not be a root of $ f_{\alpha^*}g_{\beta^*}$, contradicting that $ x$ is in the closed set to begin with. Thus we have verified that this actually defines the union of two closed sets. By induction, this gives us finite unions of closed sets being closed.
So the Zariski topology is in fact a valid topology on $ \mathbb{R}^n$, and it is not hard to see that if $ k$ is any field, then there is a well-defined Zariski topology on the set $ k^n$. In fact, studying this topology very closely yields a numerous amount of computational tools to solve problems like robot motion planning and automated theorem proving. We plan to investigate these topics in the future of this blog once we cover a little bit of ring theory, but for now the Zariski topology serves as a wonderful example of a useful topology.
Homeomorphisms
One major aspect of mathematics is how to find the correct notion of calling two things “equivalent.” In the theory of metric spaces, the strongest possible such notion is called an isometry. That is, two metric spaces $ X, Y$ with metrics $ d_X, d_Y$ are called isometric if there exists a surjective function $ f: X \to Y$ which preserves distance (i.e. $ d_X(x,y) = d_Y(f(x), f(y))$ for all $ x,y \in X$, and the image $ f(X)$ is all of $ Y$). It is not hard to see that such functions are automatically both continuous and injective. The function $ f$ is called an isometry.
Now we can call two metric spaces “the same” if they are isometric. And they really are the same for all intents and purposes: the isometry $ f$ simply relabels the points of $ X$ as points of $ Y$, and maintains the appropriate distances. Indeed, isometry is such a strong notion of equivalence that isometries of Euclidean space are completely classified.
However, because we don’t have distances in a topological space, the next best thing is a notion of equivalence based on continuity. This gives rise to the following definition.
Definition: A function $ f: X \to Y$ between topological spaces is a homeomorphism if it is continuous, invertible, and its inverse $ f^{-1}$ is also continuous. In this case we call $ X$ and $ Y$ homeomorphic, and we write $ X \cong Y$.
In other words, we consider two topological spaces to be “the same” if one can be continuously transformed into the other in an invertible way. In still other words, a homeomorphism is a way to show that two topologies “agree” with each other. Indeed, since a topology is the only structure we have on our spaces, saying that two topologies agree is the strongest thing that can be said. (Of course, for many topological spaces we will impose other kinds of structure, but the moral still holds.)
As a first example, it is not hard to see that one can continuously transform a square into a circle (where these are considered subsets of the plane $ \mathbb{R}^2$ with the Euclidean topology):
Transform a circle into a square by projecting from the center of the circle (source: Quora).
To see how this is done, take any point $ x$ on the circle, and draw a ray from the center of the circle through $ x$. This line will intersect the square somewhere, and we can define $ f(x)$ to be that point of intersection. It is easy to see that a slight perturbation of the choice of $ x$ will only slightly change the image $ f(x)$, and that this mapping is invertible. This flavor of proof is standard in topology, because giving an argument in complete rigor (that is, defining an explicit homeomorphism) is extremely tedious and neither enlightening nor satisfying. And while there are a few holes in our explanation (for instance, what exactly is the topology of the square?), the argument is morally correct and conveys to the reader one aspect of what a homeomorphism can do.
On the other hand, in our first two examples of topological space, the discrete and indiscrete topologies, homeomorphisms are nonsensical. In fact, any two spaces with the discrete topology whose underlying sets have the same cardinality are homeomorphic, and the same goes for the indiscrete topology. This is simply because every function from a discrete space is continuous, and any function to an indiscrete space is continuous. In some sense, such topological spaces are considered pathological, because no topological tools can be used to glean any information about their structure.
As expected, the composition of two homeomorphisms is again a homeomorphism. From this it follows that homeomorphism is an equivalence relation, and so we can try to classify all topological spaces (or some interesting family of topological spaces) up to homeomorphism.
Of course, there are some very simple spaces that cannot be homeomorphic. For instance (again in the Euclidean topology), a circle is not homeomorphic to a line. While we will not prove this directly (that would require more tedious computations), there are good moral reasons why it is true. We will later identify a list of so-called topological invariants. These are properties of a topological space that are guaranteed to be preserved by homeomorphisms. In other words, if a space $ X$ has one of these properties and another space $ Y$ does not, then $ X$ and $ Y$ cannot be homeomorphic. A simple-minded topological invariant relevant to the question at hand is the existence of a “hole” in the space. Since the circle has a hole but the line does not, they cannot be homeomorphic. We will spend quite a lot of time developing more advanced topological invariants, but in the next primer we will list a few elementary and useful ones.
Of course there are many beautiful and fascinating topological spaces in higher dimensions. We will close this post with a description of a few of the most famous ones in dimension two (and, of course, we are ignoring what “dimension” rigorously means).
One nice space is the torus:

The torus (credit Wikipedia)
Otherwise known as the surface of a donut, a common mathematical joke is that a topologist cannot tell the difference between a donut and a coffee cup. Indeed, the two spaces are homeomorphic, so they are the same from a topologist’s point of view:

An explicit homeomorphism between a torus and a coffee cup (source Wikipedia).
This is a testament to the flexibility of homeomorphisms.
Another nice space is the Klein Bottle:

The Klein Bottle (source Wikipedia)
The Klein bottle is a fascinating object, because it does not “live” in three dimensions. Despite that it appears to intersect itself in the picture above, this is just a visualization of the Klein Bottle. It actually lives in four-dimensional space (which is impossible to visualize) and in this setting the space does not intersect itself. We say that the Klein Bottle can be embedded into $ \mathbb{R}^4$, but not $ \mathbb{R}^3$, and we will make this notion rigorous in the next primer. While this is not at all obvious, the torus and the Klein bottle are not homeomorphic.
The last space we will introduce is the real projective plane. This space, commonly denoted $ \mathbb{R}\textup{P}^2$, also does not embed in three-dimensional Euclidean space. Unlike the Klein Bottle, $ \mathbb{R}\textup{P}^2$ has no reasonable visualization, so a picture would be futile. Instead, we can think of it as a particular modification of a sphere: take a hollow sphere and “glue together” any pair of antipodal points (that is, points which are on the same line through the center of the sphere). This operation of “gluing,” although it may seem awkward, does define a perfectly good topological space (we will cover the details in the next primer). Of course, it is extremely hard to get a good idea of what it looks like, except to say that it is “kind of” like a sphere with some awkward twists in it. Again, $ \mathbb{R}\textup{P}^2$ is not homeomorphic to either of the torus or the Klein Bottle.
This only scratches the surface of commonly seen topological spaces (the Möbius strip comes to mind, for instance). While we don’t have nearly enough space or time on this blog to detail very many of them, next time we will investigate ways to take simple topological spaces and put them together to make more complex spaces. We will rigorize the notion of “gluing” spaces together, along with other common operations. We will also spend some time developing topological invariants which allow us to “count” the number of “holes” in a space. These invariants will become the sole focus of our applications of topology to data analysis.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.