This post comes in preparation for a post on decision trees (a specific type of tree used for classification in machine learning). While most mathematicians and programmers are familiar with trees, we have yet to discuss them on this blog. For completeness, we’ll give a brief overview of the terminology and constructions associated with trees, and describe a few common algorithms on trees. We will assume the reader has read our first primer on graph theory, which is a light assumption. Furthermore, we will use the terms node and vertex interchangeably, as mathematicians use the latter and computer scientists the former.
Definitions
Mathematically, a tree can be described in a very simple way.
Definition: A path $ (v_1, e_1, v_2, e_2, \dots, v_n)$ in a graph $ G$ is called a cycle if $ v_1 = v_n$. Here we assume no vertex is repeated in a path (we use the term trail for a path which allows repeated vertices or edges).
Definition: A graph $ G$ is called connected if every pair of vertices has a path between them. Otherwise it is called disconnected.
Definition: A connected graph $ G$ is called a tree if it has no cycles. Equivalently, $ G$ is a tree if for any two vertices $ v,w$ there is a unique path connecting them.
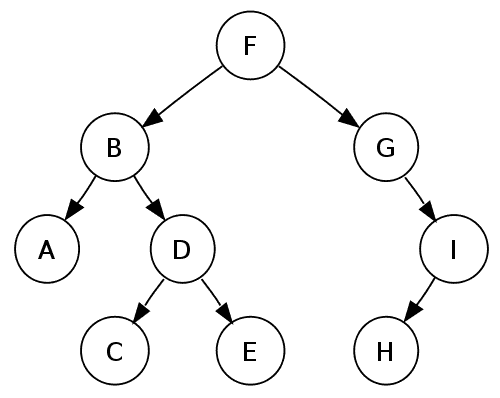
The image at the beginning of this post gives an example of a simple tree. Although the edges need not be directed (as implied by the arrows on the edges), there is usually a sort of hierarchy associated with trees. One vertex is usually singled out as the root vertex, and the choice of a root depends on the problem. Below are three examples of trees, each drawn in a different perspective. People who work with trees like to joke that trees are supposed to grow upwards from the root, but in mathematics they’re usually drawn with the root on top.
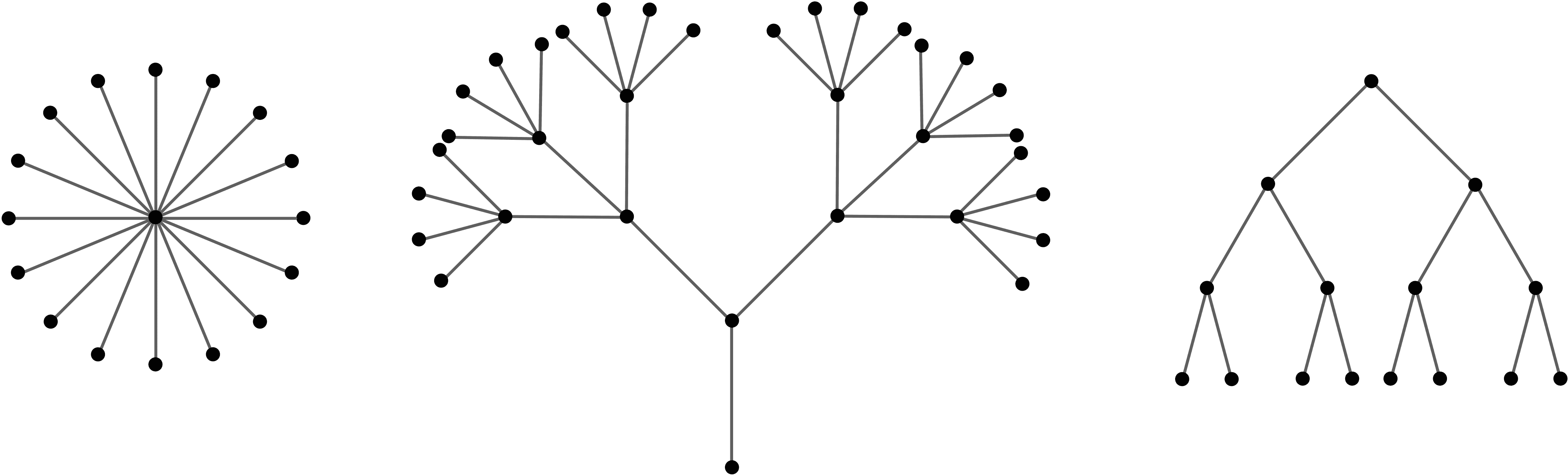
We call a tree with a distinguished root vertex a rooted tree, and we denote it $ (T,r)$, where $ T$ is the tree and $ r$ is the root. The important thing about the hierarchy is that it breaks the tree into discrete “levels” of depth. That is, we call the depth of a vertex $ v$ the length of the shortest path from the root $ r$ to $ v$. As you can see in the rightmost tree in the above picture, we often draw a tree so that its vertices are horizontally aligned by their depth. Continuing with nature-inspired names, the vertices at the bottom of the tree (more rigorously, vertices of degree 1) are called leaves. A vertex which is neither a leaf nor the root is called an internal node. Extending the metaphor to family trees, given a vertex $ v$ of depth $ n$, the adjacent vertices of depth $ n+1$ (if there are any) are called the child nodes (or children) of $ v$. Similarly, $ v$ is called the parent node of its children. Extrapolating, any node on the path from $ v$ to the root $ r$ is an ancestor of $ v$, and $ v$ is a descendant of each of them.
As a side note, all of this naming is simply a fancy way of imposing a partial ordering on the vertices of a tree, in that the vertex $ v \leq w$ if $ v$ is on the path from $ r$ to $ w$. Using some mathematical lingo, a “chain” in this partial order is simply a traversal down the tree from some stopping vertex. All of the names simply make this easier to talk about in English: $ v \leq w$ if and only if $ v$ is an ancestor of $ w$. Of course, there are also useful total orderings on a tree (where you can compare two vertices, neither of which is a descendant of the other), and we will describe some later in this post.
In applications, there is usually some data associated with the vertices and edges of a tree. For example, in our future post on decision trees, the vertices will represent attributes of the data, and the edges will represent particular values for those attributes. A traversal down the tree from root to a leaf will correspond to an evaluation of the classification function. The meat of the discussion will revolve around how to construct a sensible tree.
The important thing about depth in trees is that, given sufficient bounds on the degree of each vertex, the depth of a tree which is not egregiously unbalanced is logarithmic in the number of vertices. In fact, most trees in practice will satisfy this. Perhaps the most common kind is a so-called binary tree, in which each internal node has degree at most 3 (two children, one parent). To see that this satisfies the logarithmic claim, simply count nodes by depth: the $ k$-th level of the tree can have at most $ 2^k$ vertices. And so if all of the levels are filled (the tree is not “unbalanced”) and the tree has depth $ n$, then the number of nodes in the tree is $ \sum_{i=0}^n 2^i = 2^{n+1} – 1$. Taking a logarithm recovers a term that is linear in $ n$, and the same argument holds if we can fix a global bound on the degree of each internal node. The rightmost picture in the image above gives an example of a complete binary tree of 15 nodes.
In other words, if one can model their data in a binary tree, then searching through the data takes logarithmic time in the number of data points! For those readers unfamiliar with complexity theory, that is wicked fast. To put things into perspective, it’s commonly estimated that there are less than a billion websites on the internet. If one could search through all of these in logarithmic time, it would take roughly 30 steps to find the right site (and that’s using a base of 2; in base 10 it would take 9 steps).
As a result, much work has been invested in algorithms to construct and work with trees. Indeed the crux of many algorithms is simply in translating a problem into a tree. These data structures pop up in nearly every computational field in existence, from operating systems to artificial intelligence and many many more.
Representing a Tree in a Computer
The remainder of this post will be spent designing a tree data structure in Python and writing a few basic algorithms on it. We’re lucky to have chosen Python in that the class representation of a tree is particularly simple. The central compound data type will be called “Node,” and it will have three associated parts:
- A list of child nodes, or an empty list if there are none.
- A parent node, or “None” if the node is the root.
- Some data associated with the node.
In many strongly-typed languages (like Java), one would need to be much more specific in number 3. That is, one would need to construct a special Tree class for each kind of data associated with a node, or use some clever polymorphism or template programming (in Java lingo, generics), but the end result is often still multiple versions of one class.
In Python we’re lucky, because we can add or remove data from any instance of any class on the fly. So, for instance, we could have our leaf nodes use different internal data as our internal nodes, or have our root contain additional information. In any case, Python will have the smallest amount of code while still being readable, so we think it’s a fine choice.
The node class is simply:
class Node:
def __init__(self):
self.parent = None
self.children = []
That’s it! In particular, we will set up all of the adjacencies between nodes after initializing them, so we don’t need to put anything else in the constructor.
Here’s an example of using the class:
root = Node()
root.value = 10
leftChild = Node()
leftChild.value = 5
rightChild = Node()
rightChild.value = 12
root.children.append(leftChild)
root.children.append(rightChild)
leftChild.parent = root
rightChild.parent = root
We should note that even though we called the variables “leftChild” and “rightChild,” there is no distinguishing from left and right in this data structure; there is just a list of children. While in some applications the left child and right child have concrete meaning (e.g. in a binary search tree where the left subtree represents values that are less than the current node, and the right subtree is filled with larger elements), in our application to decision trees there is no need to order the children.
But for the examples we are about to give, we require a binary structure. To make this structure more obvious, we’ll ugly the code up a little bit as follows:
class Node:
def __init__(self):
self.parent = None
self.leftChild = None
self.rightChild = None
In-order, Pre-order, and Post-order Traversals
Now we’ll explore a simple class of algorithms that traverses a tree in a specified order. By “traverse,” we simply mean that it visits each vertex in turn, and performs some pre-specified action on the data associated with each. Those familiar with our post on functional programming can think of these as extensions of the “map” function to operate on trees instead of lists. As we foreshadowed earlier, these represent total orders on the set of nodes of a tree, and in particular they stand out by how they reflect the recursive structure of a tree.
The first is called an in-order traversal, and it is perhaps the most natural way to traverse a tree. The idea is to hit the leaves in left-to-right order as per the usual way to draw a tree, ignoring depth. It generalizes easily from a tree with only three nodes: first you visit the left child, then you visit the root, then you visit the right child. Now instead of using the word “child,” we simply say “subtree.” That is, first you recursively process the left subtree, then you process the current node, then you recursively process the right subtree. This translates easily enough into code:
def inorder(root, f):
''' traverse the tree "root" in-order calling f on the
associated node (i.e. f knows the name of the field to
access). '''
if root.leftChild != None:
inorder(root.leftChild, f)
f(root)
if root.rightChild != None:
inorder(root.rightChild, f)
For instance, suppose we have a tree consisting of integers. Then we can use this function to check if the tree is a binary search tree. That is, we can check to see if the left subtree only contains elements smaller than the root, and if the right subtree only contains elements larger than the root.
def isBinarySearchTree(root):
numbers = []
f = lambda node: numbers.append(node.value)
inorder(root, f)
for i in range(1, len(numbers)):
if numbers[i-1] > numbers[i]:
return False
return True
As expected, this takes linear time in the number of nodes in the tree.
The next two examples are essentially the same as in-order; they are just a permutation of the lines of code of the in-order function given above. The first is pre-order, and it simply evaluates the root before either subtree:
def preorder(root, f):
f(root)
if root.leftChild != None:
preorder(root.leftChild, f)
if root.rightChild != None:
preorder(root.rightChild, f)
And post-order, which evaluates the root after both subtrees:
def postorder(root, f):
if root.leftChild != None:
postorder(root.leftChild, f)
if root.rightChild != None:
postorder(root.rightChild, f)
f(root)
Pre-order does have some nice applications. The first example requires us to have an arithmetical expression represented in a tree:
root = Node()
root.value = '*'
n1 = Node()
n1.value = '1'
n2 = Node()
n2.value = '3'
n3 = Node()
n3.value = '+'
n4 = Node()
n4.value = '3'
n5 = Node()
n5.value = '4'
n6 = Node()
n6.value = '-'
root.leftChild = n3
root.rightChild = n6
n3.leftChild = n1
n3.rightChild = n2
n6.leftChild = n4
n6.rightChild = n5
This is just the expression $ (1+3)*(3-4)$, and the tree structure specifies where the parentheses go. Using pre-order traversal in the exact same way we used in-order, we can convert this representation to another common one: Polish notation.
def polish(exprTree):
exprString = []
f = lambda node: exprString.append(node.value)
preorder(exprTree, f)
return ''.join(exprString)
One could also use a very similar function to create a copy of a binary tree, as one needs to have the root before one can attach any children, and this rule applies recursively to each subtree.
On the other hand, post-order traversal can represent mathematical expressions in post-fix notation (reverse-polish notation), and it can be useful for deleting a tree. This would come up if, say, each node had some specific cleanup actions required before it could be deleted, or alternatively if one is working with a dynamic memory allocation (e.g. in C) and must explicitly “free” each node to clear up memory.
So now we’ve seen a few examples of trees and mentioned how they can be represented in a program. Next time we’ll derive and implement a meatier application of trees in the context of machine learning, and in future primers we’ll cover minimum spanning trees and graph searching algorithms.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.