The Complexity of Things
Previously on this blog (quite a while ago), we’ve investigated some simple ideas of using randomness in artistic design (psychedelic art, and earlier randomized css designs). Here we intend to give a more thorough and rigorous introduction to the study of the complexity of strings. This naturally falls into the realm of computability theory and complexity theory, and so we refer the novice reader to our other primers on the subject (Determinism and Finite Automata, Turing Machines, and Complexity Classes; but Turing machines will be the most critical to this discussion).
The Problem with Randomness
What we would really love to do is be able to look at a string of binary digits and decide how “random” it is. On one hand, this is easy to do at a high level. A child would have no difficulty deciding which of the following two strings is more random:
10101010101010101010101010101010101010101010101010
00011101001000101101001000101111010100000100111101
And yet, by the immutable laws of probability, each string has an equal chance ($ 2^{-50}$) in being chosen at random from all sequences of 50 binary digits. So in a sense, the huge body of mathematics underlying probability has already failed us at this basic juncture because we cannot speak of how random one particular outcome of an experiment is. We need a new notion that overcomes this difficulty.
Definition: The Kolmogorov complexity of a string $ w$, denoted $ K(w)$ is the length of the shortest program which outputs $ w$ given no input.
While this definition is not rigorous enough to be of any use (we will reformulate it later), we can easily see why the first of the two strings above is less random. We can write a very short Python program that outputs it:
print "01" * 25
On the other hand, it is not hard to see that the shortest program that produces the second string is
print "00011101001000101101001000101111010100000100111101"
The dutiful reader will cry out in protest. How do you know that’s the shortest program? Why restrict to Python? This whole discussion is so arbitrary!
Indeed, this is probably not the strictly shortest Python program that prints out the string. In the following we’ll work entirely in binary, so the picky reader should interpret this as a print command referring to a block of binary memory. We will reify these ideas in full rigor shortly, but first let us continue with this naivete to make the coming definitions a bit easier to parse.
If we abstract away the lengths of these strings, we see that the length of the first program is $ O(1) + \log(n)$, since we need $ \log(n)$ bits to represent the number $ n/2$ in the string product. On the other hand, the second string has a program length of $ O(1) + n$, as we require the entire output string as program text.
This intuition would lead us to define a sequence of length $ n$ to be random if it has Kolmogorov complexity at least $ n$. One way to interpret this is: a string is “random” if the shortest program that outputs the string basically encodes the entire string in its source code.
We can extend this idea to talk about relative complexity. Specifically, we can speak of Python programs which accept input, and compute their output based on that input. For instance, the first of the two strings above has the program:
n = input()
print "01" * n/2
With respect to the input “50”, we see that the first string has constant complexity (indeed, this is also true of many numbers, such as 25). In other words, the string “50” contains a lot of information about the string we wish to generate (it’s length).
On the other hand, the same technique still won’t work for the second string. Even though it has length 50, that is not enough information to determine the contents of the string, which vary wildly. So the shortest program is still (probably) the one which prints out the string verbatim.
In the future, we plan to revisit the idea of relative complexity in the context of machine learning and classification; briefly, two items are similar if one has low complexity relative to the other. But for now, let us turn to the more precise definitions.
Actual Kolmogorov Complexity
We keep saying of the second string above that the shortest program is probably the one which prints the string verbatim. In fact, short of testing every single python program of shorter length, we will never know if this is true! Even if we did, our following definitions will make that discovery irrelevant. More generally, it’s an important fact that Kolmogorov complexity is an uncomputable function. That is, there is no Turing machine $ M$ which accepts as input a word $ w$ and produces its Kolmogorov complexity as output. In order to prove such miraculous things, we need to formalize the discussion in the context of Turing machines.
Let us fix a universal programming language $ L$ and speak of the Kolmogorov complexity with respect to $ L$:
Definition: The Kolmogorov complexity of a string $ w$ with respect to $ L$, denoted $ K_L(w)$ is the shortest program written in the language $ L$ which produces $ w$ as output. The conditional Kolmogorov complexity with respect to a string $ x$, denoted $ K_L(w | x)$ (spoken $ w$ given $ x$, as in probability theory), is the length of the shortest program which, when given $ x$ as input, outputs $ w$.
Before we can prove that this definition is independent of $ L$ (for all intents and purposes), we need a small lemma, which we have essentially proved already:
Lemma: For any strings $ w,x$ and any language $ L$, we have $ K_L(w | x) \leq |w| + c$ for some constant $ c$ independent of $ w, x$, and $ K_L(w) \leq |w| + c’$ for some constant $ c’$ independent of $ w$.
Proof. The program which trivially outputs the desired string has length $ |w| + c$, for whatever constant number of letters $ c$ is required to dictate that a string be given as output. This is clearly independent of the string and any input. $ \square$
It is not hard to see that this definition is invariant under a choice of language $ L$ up to a constant factor. In particular, let $ w$ be a string and fix two languages $ L, L’$. As long as both languages are universal, in the sense that they can simulate a universal Turing machine, we can relate the Kolmogorov complexity of $ w$ with respect to both languages. Specifically, one can write an interpreter for $ L$ in the language of $ L’$ and vice versa. Readers should convince themselves that for any two reasonable programming languages, you can write a finite-length program in one language that interprets and executes programs written in the other language.
If we let $ p$ be the shortest program written in $ L$ that outputs $ w$ given $ x$, and $ i$ be the interpreter for $ L$ written in $ L’$, then we can compute $ w$ given the input $ \left \langle p, x \right \rangle$ by way of the interpreter $ i$. In other words, $ K_L(w | px) \leq |i|$.
$$K_{L’}(w | x) \leq |p| + c + |i| = K_L(w | x) + c + |i| = K_L(w | x) + O(1)$$Another easy way to convince oneself of this is to imagine one knows the language $ L’$. Then the program would be something akin to:
input x
run the interpreter i on the program p with input x
Our inequalities above just describe the length of this program: we require the entire interpreter $ i$, and the entire program $ p$, to be part of the program text. After that, it’s just whatever fixed constant amount of code is required to initialize the interpreter on that input.
We call this result the invariance property of Kolmogorov complexity. And with this under our belt, we may speak of the Kolmogorov complexity of a string. We willingly ignore the additive constant difference which depends on the language chosen, and we may safely work exclusively in the context of some fixed universal Turing machine (or, say, Python, C, Racket, or Whitespace; pick your favorite). We will do this henceforth, denoting the Kolmogorov complexity of a string $ K(w)$.
Some Basic Facts
The two basic facts we will work with are the following:
- There are strings of arbitrarily large Kolmogorov complexity.
- Most strings have high complexity.
And we will use these facts to prove that $ K$ is uncomputable.
The first point is that for any $ n$, there is a string $ w$ such that $ K(w) \geq n$. To see this, we need only count the number of strings of smaller length. For those of us familiar with typical combinatorics, it’s just the Pigeonhole Principle applied to all strings of smaller length.
Specifically, there is at most one string of length zero, so there can only be one string with Kolmogorov complexity zero; i.e., there is only one program of length zero, and it can only have one output. Similarly, there are two strings of length one, so there are only two strings with Kolmogorov complexity equal to one. More generally, there are $ 2^i$ strings of length $ i$, so there are at most $ \sum_{i = 0}^{n-1} 2^i$ strings of Kolmogorov complexity less than $ n$. However, as we have seen before, this sum is $ 2^n – 1$. So there are too many strings of length $ n$ and not enough of smaller length, implying that at least one string of length $ n$ has Kolmogorov complexity at least $ n$.
The second point is simply viewing the above proof from a different angle: at least 1 string has complexity greater than $ n$, more than half of the $ 2^n$ strings have complexity greater than $ n-1$, more than three quarters of the strings have complexity greater than $ n-2$, etc.
Rigorously, we will prove that the probability of picking a string with $ K(x) \leq n – c – 1$ is smaller than $ 1/2^c$. Letting $ S$ be the set of all such strings, we have an injection $ S \hookrightarrow $ the set of all strings of length less than $ n – c- 1$, and there are $ 2^{n-c} – 1$ such strings, so $ |S| \leq 2^{n-c} – 1$, giving the inequality:
$$\displaystyle \frac{|S|}{2^n} \leq \frac{2^{n-c} – 1}{2^n} = \frac{1}{2^c} – \frac{1}{2^n} < \frac{1}{2^c}$$In other words, the probability that a randomly chosen string $ w$ of length $ n$ has $ K(w) \geq n-c$ is at least $ 1 – 1/2^c$.
The strings of high Kolmogorov complexity have special names.
Definition: We call a string $ w$ such that $ K(w) \geq |w|$ a Kolmogorov random string, or an incompressible string.
This name makes sense for two reasons. First, as we’ve already mentioned, randomly chosen strings are almost always Kolmogorov random strings, so the name “random” is appropriate. Second, Kolmogorov complexity is essentially the ideal compression technique. In a sense, strings with high Kolmogorov complexity can’t be described in any shorter language; such a language would necessarily correspond to a program that decodes the language, and if the compression is small, so is the program that decompresses it (these claims are informal, and asymptotic).
Uncomputability
We will now prove the main theorem of this primer, that Kolmogorov complexity is uncomputable.
Theorem: The Kolmogorov complexity function $ w \mapsto K(w)$ is uncomputable.
Proof. Suppose to the contrary that $ K$ is computable, and that $ M$ is a Turing machine which computes it. We will construct a new Turing machine $ M’$ which computes strings of high complexity, but $ M’$ will have a short description, giving a contradiction.
Specifically, $ M’$ iterates over the set of all binary strings in lexicographic order. For each such string $ w$, it computes $ K(w)$, halting once it finds a $ w$ such that $ K(w) \geq |w| = n$. Then we have the following inequality:
$$n \leq K(w) \leq \left | \left \langle M’, n \right \rangle \right | + c$$Here, the angle bracket notation represents a description of the tuple $ (M’, n)$, and $ c$ is a constant depending only on $ M’$, which is fixed. The reason the inequality holds is just the invariance theorem: $ \left \langle M’, n \right \rangle$ is a description of $ w$ in the language of Turing machines. In other words, the universal Turing machine which simulates $ M’$ on $ n$ will output $ w$, so the Kolmogorov complexity of $ w$ is bounded by the length of this description (plus a constant).
Then the length of $ \left \langle M’, n \right \rangle$ is at most $ \log(n) + \left | \left \langle M’ \right \rangle \right | + c’$ for some constant $ c’$, and this is in turn $ \log(n) + c”$ for some constant $ c”$ (as the description of $ M’$ is constant). This gives the inequality
$$n \leq \log(n) + c”$$But since $ \log(n) = o(n)$, we may pick sufficiently large $ n$ to achieve a contradiction. $ \square$
We can interpret this philosophically: it is impossible to tell exactly how random something is. But perhaps more importantly, this is a genuinely different proof of uncomputability from our proof of the undecidability of the Halting problem. Up until now, the only way we could prove something is uncomputable is to reduce it to the Halting problem. Indeed, this lends itself nicely to many new kinds of undecidability-type theorems, as we will see below.
The reader may ask at this point, “Why bother talking about something we can’t even compute!?” Indeed, one might think that due to its uncomputability, Kolmogorov complexity can only provide insight into theoretical matters of no practical concern. In fact, there are many practical applications of Kolmogorov complexity, but in practice one usually gives a gross upper bound by use of the many industry-strength compression algorithms out there, such as Huffman codes. Our goal after this primer will be to convince you of its remarkable applicability, despite its uncomputability.
Consequences of Uncomputability and Incompressibility
One immediate consequence of the existence of incompressible strings is the following: it is impossible to write a perfect lossless compression algorithm. No matter how crafty one might be, there will always be strings that cannot be compressed.
But there are a number of other, more unexpected places that Kolmogorov complexity fills a niche. In computational complexity, for instance, one can give a lower bound on the amount of time it takes a single-tape Turing machine to simulate a two-tape Turing machine. Also in the realm of lower bounds, one can prove that an incompressible string $ w$ of length $ 2^n$, which can be interpreted as a boolean function on $ n$ variables, requires $ \Omega(2^n/n)$ gates to express as a circuit.
It also appears outside of theoretical computer science. In, for instance, the study of entropy in dynamical systems (specifically, thermodynamics), one can make the following pictorial remark:
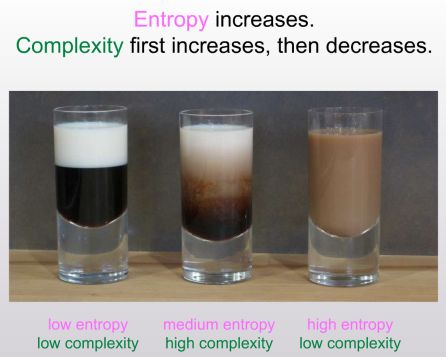
In fact, the author of this image, Scott Aaronson (whom we’ve seen before in our exploration of the Complexity Zoo) even proposes an empirical test of this fact: simulate a discretized coffee cup and try to compress the data at each step, graphing the resulting lengths to see the trends. This even sounds like a good project for this blog!
The applications don’t end there, though. Researchers have used the theory of Kolmogorov complexity to tackle problems in machine learning, clustering, and classification. Potentially, any subject which is concerned with relating pieces of information could benefit from a Kolmogorov-theoretic analysis.
Finally, we give a proof that the existence of Kolmogorov complexity provides an infinite number of mathematical statements which are unprovable.
Theorem: Fix a formalization of mathematics in which the following three conditions hold:
- If a statement is provable then it is true.
- Given a proof and a statement, it is decidable whether the proof proves the statement.
- For every binary string $ x$ and integer $ k$, we can construct a statement $ S(x,k)$ which is logically equivalent to “the Kolmogorov complexity of $ x$ is at least $ k$”.
Then there is some constant $ t$ for which all statements $ S(x,k)$ with $ k > t$ are unprovable.
Proof. We construct an algorithm to find such proofs as follows:
On an input k,
Set m equal to 1.
Loop:
for all strings x of length at most m:
for all strings P of length at most m:
if P is a proof of S(x,k), output x and halt
m = m+1
Suppose to the contrary that for all $ k$ there is an $ x$ for which the statement $ S(x,k)$ is provable. It is easy to see that the algorithm above will find such an $ x$. On the other hand, for all such proofs $ P$, we have the following inequality:
$$k \leq K(x) \leq \left | \left \langle M, k \right \rangle \right | + c = \log(k) + c’$$Indeed, this algorithm is a description of $ x$, so its length gives a bound on the complexity of $ x$. Just as in the proof of the uncomputability of $ K$, this inequality can only hold for finitely many $ k$, a contradiction. $ \square$
Note that this is a very different unprovability-type proof from Gödel’s Incompleteness Theorem. We can now construct with arbitrarily high probability arbitrarily many unprovable statements.
Look forward to our future posts on the applications of Kolmogorov complexity! We intend to explore some compression algorithms, and to use such algorithms to explore clustering problems, specifically for music recommendations.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.